Analogical Q/A Training
When people learn to operate in new domains, they do not start learning language from scratch. They reuse general-purpose language knowledge and skills, and rapidly adapt to new domains. Analogical Q/A training enables general-purpose semantic parsers to be rapidly adapted to new tasks and domains, with high data-efficiency. Moreover, it can use semantics tied to a broad ontology to self-annotate, thereby reducing the training work considerably. The AQA approach analyzes questions and answers (with answers either annotated or self-annotated) and produces query cases that are retrieved and used via analogical matching to construct queries.
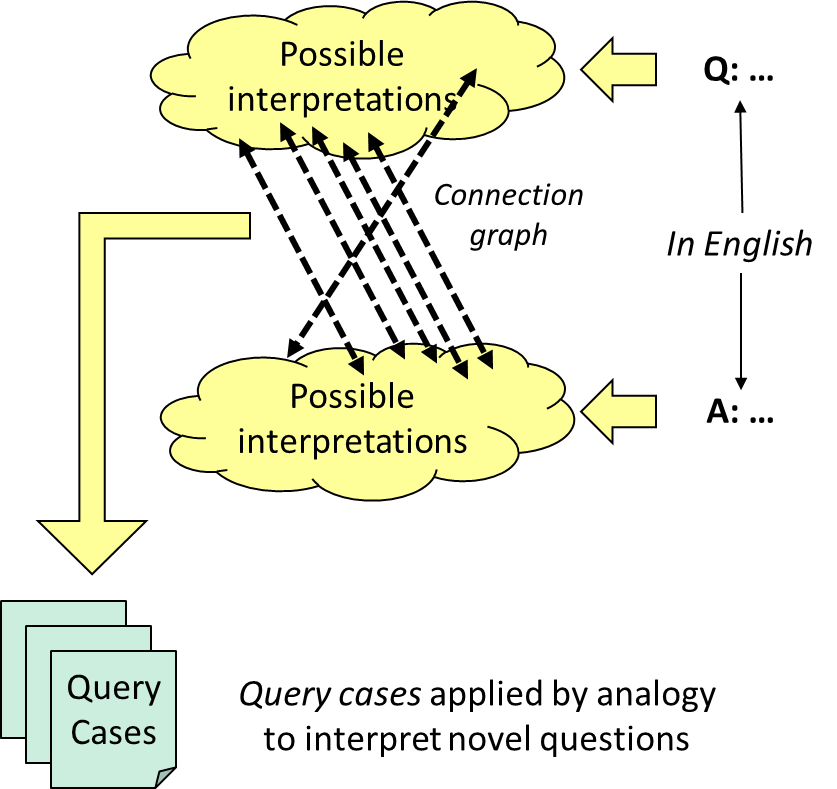
To demonstrate data efficiency, consider training on just these two examples from the classic Geoquery domain:
- Train: Q:
Which capitals are in states that border Texas?
A:Baton Rouge, Little Rock, Oklahoma City, Santa Fe.
- Train: Q:
What rivers are in Utah?
A:Colorado, Green, San Juan.
Given just these two training examples, a Companion using AQA training can now answer
- Test: Q:
What rivers flow through states that Alabama borders?
- Test: Q:
What are the cities in states through which the Mississippi flows?
- Test: Q:
What are the cities in states that border states through which the Mississippi flows?
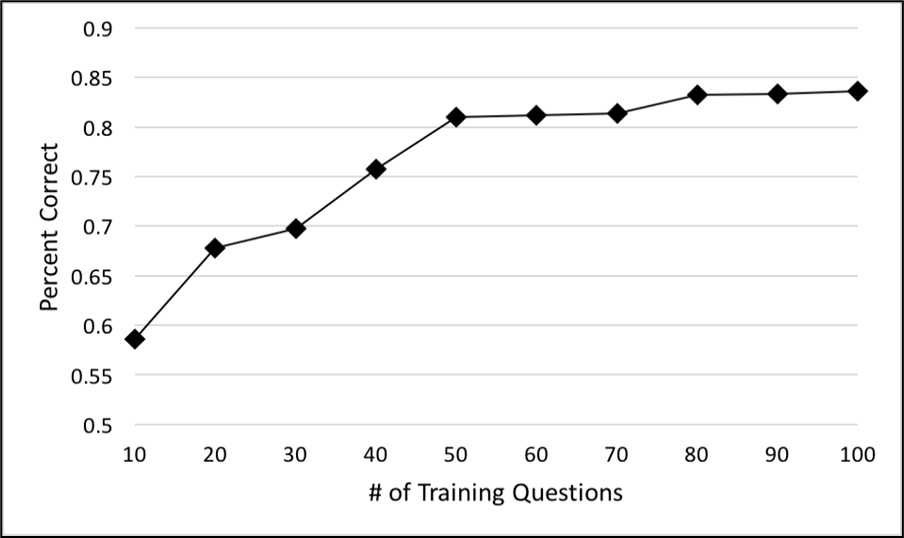
as well as any other question that can be understood as a composition of the query cases it has learned thus far. Traditional machine learning systems typically need around 600 training examples to learn a semantic parser for Geoquery. The explainability of analogical learning enables the construction of optimal training sequences, so we can explore what the minimum number of examples might be. It turns out that 50 examples suffice to achieve comparable performance.
Analogical Q/A training has been used with several other datasets, and is used in the Computer Science Department Kiosk, a deployed Companion-based system which provides information about the department to visitors.
Selected Relevant Papers
- Crouse, M., MFate, C.J., and Forbus, K.D. (2018). Learning from Unannotated QA Pairs to Analogically Disambiguate and Answer Questions. Proceedings of AAAI 2018.
- Crouse, M., McFate, C.J., & Forbus, K. (2018). Learning to Build Qualitative Scenario Models from Natural Langauge. Proceedings of QR 2018, Stockholm.
- Ribeiro, D., Hinrichs, T., Crouse, M., Forbus, K., Chang, M., and Witbrock, M. (2019). Predicting State Changes in Procedural Text using Analogical Question Answering. In Proceedings of the Seventh Annual Conference on Advances in Cognitive Systems. Cambridge, MA.
Relevant Projects
Towards Intelligent Agents that Learn by Multimodal Communication