Hybrid Primal Sketch
Marr’s original Primal Sketch theory and system led to a revolution in computer vision. The identification of edges as a primitive form of symbolic representation, grounded in quantitative properties, computed by mammalian vision systems as a stable intermediate representation for subsequent analyses, led to substantial progress on many problems in vision science. Our hypothesis is that we can use progress in deep learning vision modules, combined with the idea of edges as an intermediate representation which are then used to construct qualitative visual representations of shapes and scenes, can provide, in conjunction with analogical processing, more human-like learning.
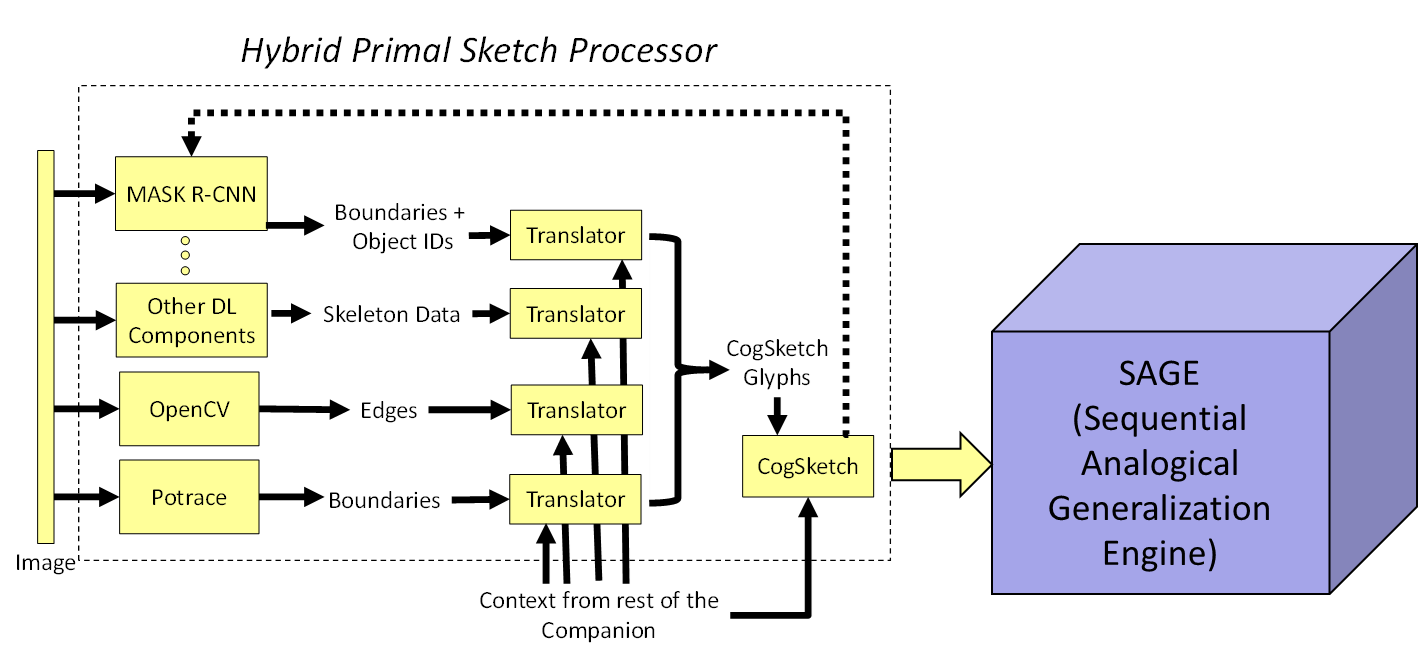
We have now implemented a prototype Hybrid Primal Sketch Processor (HPSP) to experiment with these ideas. It consists of a two-stage pipeline, as shown below. We use an ensemble of off-the-shelf edge finders and off-the-shelf DL components (currently Mask-RCNN and Faster-RCNN) to provide edges and boundary masks of objects in images for input to CogSketch, our model of high-level human vision. Bounding boxes or boundaries are provided to CogSketch as glyphs, i.e. visual entities, which it then decomposes to produce descriptions of object shapes (i.e. Geons; Chen et al. 2019) and constructs visual relationships between glyphs to produce descriptions of scenes. Object identifiers produced by the DL modules, i.e. words, are translated into the NextKB ontology used by CogSketch via our large-scale natural language lexicon.
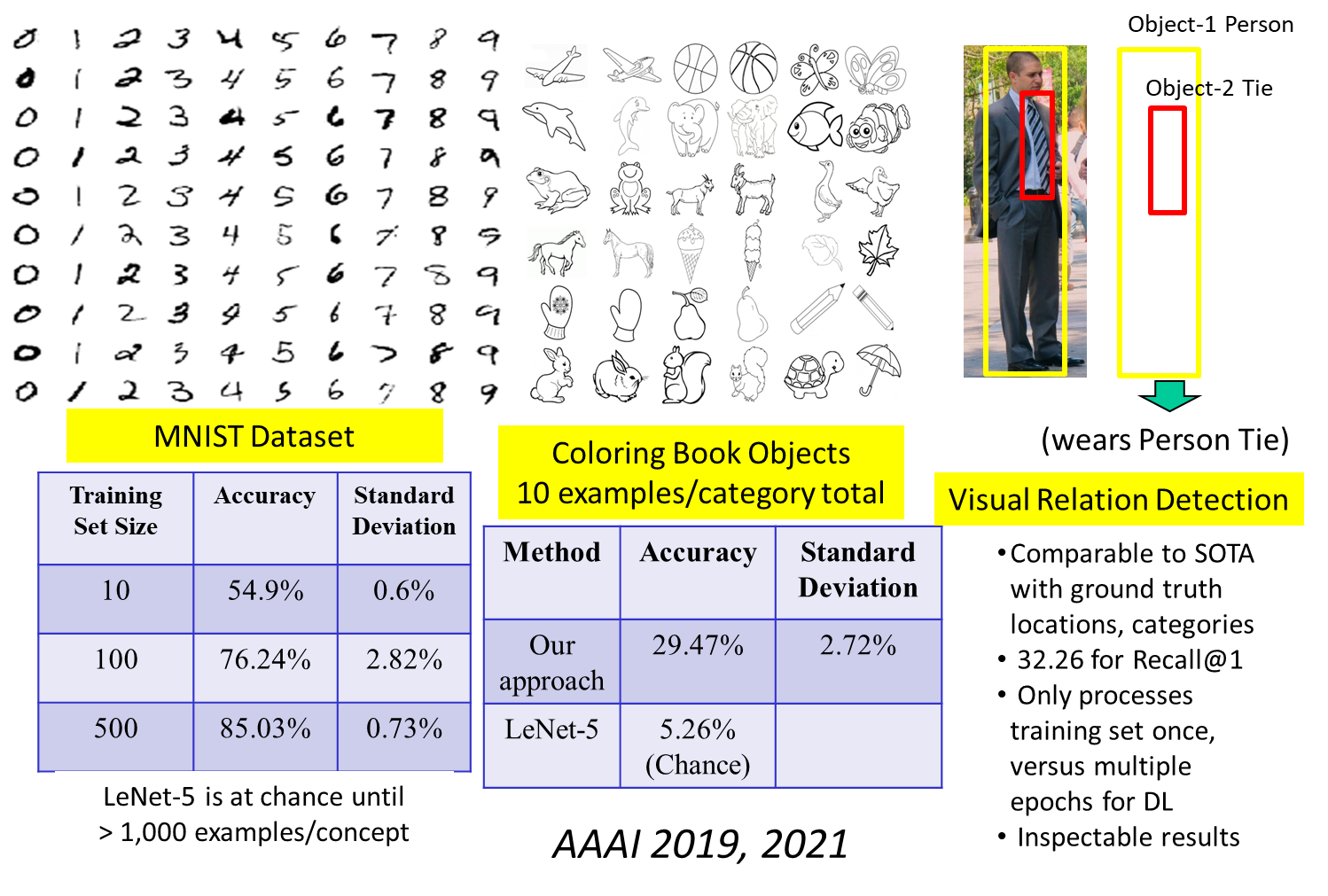
We have tested these ideas on several datasets, as summarized below.
We also have a video pipeline using similar ideas, using QSRLib to segment a Kinect video stream and using CogSketch to construct scene representations for each qualitatively distinct temporal segment, which are then used to learn human behaviors via analogical generalization.
Relevant Papers
- Chen, K. and Forbus, K.D. (2018). Action Recognition from Skeleton Data via Analogical Generalization over Qualitative Representations. Proceedings of AAAI 2018.
- Chen, K., Rabkina, I., McLure, M., & Forbus, K. (2019) Human-like Sketch Object Recognition via Analogical Learning. AAAI 2019.
- Chen, K. & Forbus, K. (2021) Visual Relation Detection using Hybrid Analogical Learning. Proceedings of AAAI 2021.
Relevant Projects
 Towards Intelligent Agents that Learn by Multimodal Communication
Towards Intelligent Agents that Learn by Multimodal Communication ![]()